6. 对话式 AI 的认知与能力拓展
开发者导读:
在前一章中,通过 STT、LLM、TTS,我们已经完成了最小可行性的 对话式 AI 搭建,但一个真正成熟的 对话式 AI,不只是“能听、能想、能说”。它需要能 执行动作(Tool Call),记住过去(Memory),查找外部信息(RAG),甚至能 表达个性与情绪(Avatar & Emotion)。这些能力让 对话式 AI 从“语音助手”变成“智能伙伴”。
本章目标
本章将带你理解这些进阶功能的原理、价值与实现方式。
我们会从 功能执行(Function Call) 开始,到 记忆与检索(Memory & RAG),再到 人格与情感(Avatar & Emotion),逐步展示 对话式 AI 如何从反应式对话,进化为主动理解与行动的智能体。
读完本章,你将能够:
理解 Tool Call 在语音场景中的作用,以及如何通过它让 对话式 AI “真正做事”;
掌握 Memory 与 RAG 在持续性对话与知识问答中的协同机制;
认识 对话式 AI 在多模态表达(声音、表情、人格)上的设计方法;
了解这些能力在实时系统中对延迟、成本与架构的影响;
思考如何在实际应用中平衡性能、延迟与个性化体验。
6.1 Tool Call:让 AI 执行动作
在一个典型的 对话式 AI 中,ASR 负责“听”,TTS 负责“说”,LLM 负责“想”。但如果它只能回答问题,却不能真正去执行任务——比如订机票、查日程、发送邮件——那它仍然只是一个“语言模型”,而不是一个“智能助手”。
Tool Call 的引入,正是让大语言模型(LLM)从“思考者”变成“行动者”。它让 AI 可以主动调用外部系统、获取实时数据、执行操作,从而突破 LLM 的封闭边界。简而言之:
Tool Call = 给 AI 一双手。
有了 ToolCall,对话式 AI 不仅能“理解你说的话”,还能“去做你想让它做的事”。它能调用天气 API 查询今天的温度,能操作你的日历安排会议,能打开车库门、发送语音消息、生成报表。
这就是 ToolCall 之所以被视为“现代 Conversational AI 的分水岭”的原因。它让模型不再被动回答,而是具备主动行动、访问实时世界的能力。
6.1.1 什么是 Tool Call
从技术角度看,Tool Call 是一种由 LLM 主动发起的函数调用机制,通过 API 调用实现。它允许模型在对话中生成一个结构化的函数调请求(通常为 JSON),然后由外部系统解析、执行并返回结果。
与传统 API 调用不同,ToolCall 的核心区别在于:
决定何时调用、调用哪个函数、用什么参数,全部由 LLM 自主判断。
开发者只需向模型提供“工具清单”与“使用说明”。
这让 LLM 拥有了一个可扩展的“工具箱”,每个工具都可以是一种能力的延伸:联网查询、数据库检索、文件处理、智能控制……
6.1.2 Tool Call 的工作原理
想要在你的 Conversation AI 当中实现 Toocall ,要经历三步走:
函数签名注册 (Function Signature Registration)
意图识别与工具调用 (Intent Recognition & Tool Call Generation)
执行与结果返回 (Execution & Result Parsing)
第一步:函数签名注册(Function Signature Registration)
首先,开发者需要告诉 LLM 它有哪些工具可用。那么首先,你需要向大模型去正确的注册你所提供给他的工具,告诉他,你提供了哪些工具,每个工具都能做什么,以及这个工具想要执行,需要哪些信息?
执行者:开发者来做。他们会定义一系列 JSON 对象,每个对象代表一个工具。
长什么样? 每个 JSON 对象会包含:
name: 工具的名称,比如 get_current_weather。
description: 这个工具是干什么的,比如“获取指定城市当前的天气情况”。
parameters: 这个工具需要哪些输入,比如 location(地点,类型为字符串),unit(温度单位,可选)。
有什么用? 大模型会读取这些信息,并将其融入到自己的上下文(Context)中。这样,它就知道了“我能用这些工具,并且知道每个工具需要什么信息才能运行”。
第二步:意图识别与工具调用(Intent Recognition & Tool Call Generation)
这是大模型最核心的“思考”环节。
接收输入:用户输入指令,比如“北京今天天气怎么样?”
意图识别:大模型会分析这句话,识别出两个关键信息:
意图:用户想获取天气信息。
参数:地点是“北京”。
生成 JSON:基于它在步骤一中学习到的“说明书”,大模型会根据意图和参数,生成一个标准的 JSON 调用代码,比如:
{
"name": "get_current_weather",
"arguments": {
"location": "Beijing"
}
}需要注意的是,大模型不会自己去执行这个代码。它只是生成一个“待办任务清单”。
第三步:执行与结果返回(Execution & Result Parsing)
这一步就是真正干活的阶段,由外部的程序来完成。
工具调用:大模型生成的 JSON 代码会被发送给一个控制器(Controller)。这个控制器是一个独立的程序,它会根据 name 字段找到对应的外部 API 或函数,然后把 arguments 里的参数传过去。
执行与返回:外部 API(比如一个天气查询服务)被调用,它会返回一个实际的结果,比如一段文本:“北京目前多云,气温 20 摄氏度。”
反馈回大模型:这个结果会被再次传回大模型。大模型拿到这个结果后,会将其作为新的输入,和用户的原始请求、以及之前生成的 JSON 调用一起,形成一个完整的对话上下文。
最终回复:大模型会根据这个新的上下文,将结果组织成自然语言,然后回复给用户:“北京目前多云,气温是 20 摄氏度。”
如果用图的方式来表示他的执行过程,就像下面这样:
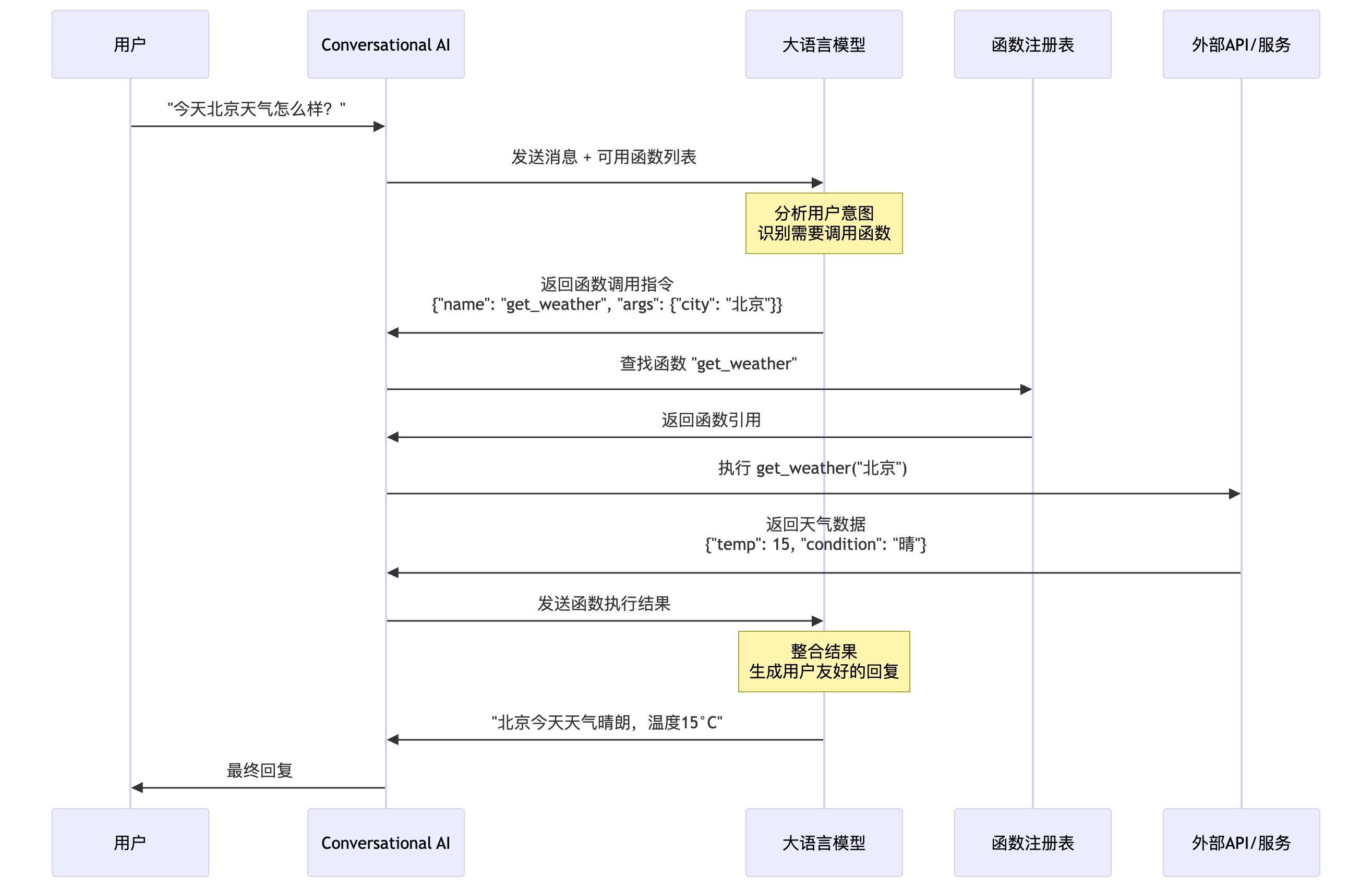
6.1.3 Tool Call 的最佳实践
Tool Call 是让 对话式 AI 变得真正「有用」的关键机制,它让大语言模型不仅能“回答问题”,还能“做事”。但如果设计不当,就容易出现调用混乱、错误频发、权限泄漏等问题。以下是一些经过实践验证的最佳实践。
函数设计(Function Design)
a. 清晰、简洁和原子化 (Clear, Concise,and Atomic)
让模型“理解”你的工具,最有效的方式就是——让工具尽可能简单。
. 一个函数,一个任务:不要让一个函数同时发邮件又发短信,分成 send_email 和 send_sms 才是正确做法。
. 命名直观:get_weather 要比 fetch_data_1 清晰得多。
. 描述完整:description 字段要明确说明用途与限制,比如“查询指定城市未来五天的天气预报”。
✅ 小贴士:大模型不擅长猜测,它依赖描述理解工具。写得越清楚,它越聪明。
b. 参数设计(Parameter Design)
清晰、语义化的参数让大模型更少出错。
参数语义化:用 city 或 location,而不是 p1。
类型安全:为每个参数定义类型(如 string、integer、boolean)。
必填与可选:明确哪些参数是必须的。例如,get_weather 中 city 是必填,unit(温度单位)可选。
c. 健壮性与容错(Robustness & Fault Tolerance)
模型不是万能的,工具出错是常态。要让系统稳得住:
返回明确的错误:比起“Internal Server Error”,返回“城市名无效”更有帮助。
统一输出格式:统一采用 JSON 格式输出,便于模型解析与后续处理。
错误处理(Error Handling)
a. 明确错误类型(Clear Error Types)
使用标准错误码(404 未找到,401 未认证,500 内部错误)。
区分输入错误(参数不合法)与系统错误(API 故障)。
提供人类可读的 message 字段说明问题原因。
b. 容错与重试(Resilience & Retry)
幂等操作可重试:查询类操作可安全自动重试;修改类操作需谨慎。
设定重试上限:防止服务故障时陷入死循环。
优雅降级:当外部 API 出错时,模型可用「替代答案」维持体验,例如:
“暂时无法获取实时天气,但根据历史数据,北京此时多为晴天。”
安全与权限(Security & Permissions)
a. 最小权限原则(Least Privilege)
工具应只获得执行任务所需的最小权限。
在沙盒环境中执行,防止单一漏洞影响整体系统。
权限按需分配,用完即收。
b. 输入验证与数据脱敏(Validation & Sanitization)
严格验证参数格式与类型,防止注入攻击。
对敏感信息(密码、身份信息)进行脱敏处理。
明确大模型与工具的边界:模型不能直接访问数据库或外部资源,所有操作必须通过受控接口。
6.2 记忆 memory:让AI 记住过去
人与人之间的交流之所以自然,是因为我们有记忆。我们能记得上次的谈话主题、对方的语气与喜好,也能在新的对话中自然衔接。如果一个朋友每次见面都完全忘记你是谁、聊过什么,这段关系会变得生硬而浅薄。多数对话式 AI 目前就是这样的“健忘朋友”。
每次交互都从零开始,无法记住你是谁、说过什么、喜欢什么——这种状态被称为无状态(Stateless)。即使模型拥有较大的上下文窗口,这种“记忆”也只存在于单次对话中,一旦会话结束,一切都会消失。而真正的记忆(Memory),能让 AI 从一次性工具进化为长期伙伴。它让系统可以:
保持上下文连续性:理解前后语义,避免重复提问。
积累个性化偏好:记住用户的习惯与风格。
从经验中学习:不断优化响应方式。
建立长期关系:在重复交互中生成信任与熟悉感。
拥有记忆的 AI,不仅能延续上一次的对话,还能理解用户的成长和变化,从而实现更自然、更人性化的交互。
6.2.1 什么是记忆
在对话式 AI 中,记忆(Memory) 是系统存储、管理与利用过往交互信息的能力。它并不仅仅是数据存储,而是一个动态的知识网络:能够提取、关联并随时间更新内容。
与传统的 RAG(Retrieval-Augmented Generation)不同,RAG 更像“即时查资料”——它只在当下检索外部知识,而不会记得用户是谁或曾经问过什么。而 Memory 则具有持续性(Continuity),它记录了:
决策(Decisions):AI 曾经做出的选择。
偏好(Preferences):用户的表达方式与喜好。
上下文(Context):对话内容与场景状态。
经验(Experiences):成功与失败的互动记录。
6.2.2 记忆的分类和机制
- 短期记忆(Short-term Memory)
用于管理当前对话的上下文,让系统能够“接着说”。它的结构非常简单直观,通常包括系统提示(system prompt)、对话历史(chat history)与当前输入(user query)。在实际应用中,这些信息会按照时间顺序组织,完整保留每一次交互的细节,从而让大模型能够准确理解当前的对话场景。例如:
[
{"role": "assistant", "content": "..."},
{"role": "user", "content": "..."}
]- 长期记忆(Long-term Memory)
长期记忆系统则用于管理跨会话、跨时间的信息,帮助 AI 记住用户的历史偏好、重要事件以及持久化的个人信息。它结合了静态和动态记忆元素,能够为用户提供更智能、更个性化的服务。
[{ "role": "assistant", "content": "... \nUser's profile:xxx" },
{"role": "user", "content": "..."},
{"role": "assistant", "content": "..."},
{ "role": "user", "content": "... \n [related
memory1]xxx \n [related memory2]xxx \n [related memory3]xxx" }
... {"role": "assistant", "content": "..."}]6.2.3 记忆的结构与管理
现代的记忆系统早已超越简单的“存储日志”,它更像是一张不断演化的知识网络。以 MemU 为例,它采用代理式记忆系统,通过以下几个关键机制实现“记忆进化”:
- 记忆提取与更新
每次对话结束后,系统会自动识别出新的有用信息(如用户偏好或任务结果),提取出来并加入记忆库。如果旧信息被证伪或过时,系统会自动更新。
- 记忆优先级排序
通过访问频率、新鲜度和任务相关性进行加权,确保最重要的信息优先被检索。
- 记忆图连接(Memory Graph Linking)
不同类型的记忆通过语义连接组成图结构。例如,“喜欢科幻电影”可以关联到“最近搜索太空题材新闻”,实现跨场景个性化。
- 语义压缩与检索
为避免记忆膨胀,系统对内容进行语义压缩,仅保留关键信息。通过语义索引快速检索与任务最相关的记忆片段。
6.2.4 Memory System 现状
要让 AI 像人类一样“记住”信息,关键在于让系统能理解数据之间的关系,而不仅仅是保存文本。现代记忆系统正逐渐从静态存储进化为动态知识网络,让 AI 能“整理、关联、更新”记忆。
- 关系网络(Relational Memory Graph)
想象一下,如果 AI 把每条记忆都看作一张卡片,这些卡片之间用线连接起来,就能形成一张巨大的知识网。比如 MemU 系统,它让 AI 像管理文件一样自主整理记忆,同时用“记忆图”把不同类别的信息关联起来。当用户提到“出差”时,系统会自动联想到“航班”“会议”“酒店”等相关记忆,实现更完整的语义理解。
- 动态自组织(Dynamic Self-Organization)
记忆系统不应是静态数据库,而是随着新信息的加入不断调整。A-MEM 系统就采用了类似“卡片笔记法”的设计,每条记忆都是独立的卡片,AI 会自动发现新卡片与旧卡片的关联。比如当用户新增“最近开始健身”的信息时,系统会将其与已有的“健康饮食”“运动装备购买记录”等卡片连接,形成更完整的用户画像。
- 分层记忆与时间衰减(Hierarchical Memory & Decay)
大多数系统采用分层设计——短期记忆用于当前对话,中期记忆保存近期任务,长期记忆记录稳定偏好。MemU 和 ZEP 都引入了时间衰减机制:信息会根据新鲜度和访问频率自动调整重要性,使系统能“记得重要的事,忘掉不再相关的事”。
6.2.5 Memory 的最佳实践
在实际工程中,记忆系统的设计不仅关乎模型能力,更影响交互体验与运行成本。以下是基于开发经验总结的实践建议。
- 会话流程管理
会话前记忆检索,构建完整上下文: 在每次用户与 AI 交互前,通过如
retrieve_default_categories()等接口,提前检索并加载用户的相关记忆(如偏好、历史事件、个人档案等),将其整合到系统提示(system prompt)中。这样可以让 AI 在对话初始阶段就拥有完整的用户画像,提升个性化和上下文理解能力。会话中避免频繁检索,保持 KV 缓存高效: 在对话进行过程中,不建议频繁调用记忆检索接口。应在会话开始前一次性加载所需记忆,随后仅依靠短期记忆(chat history)维持上下文。这样可以充分利用大模型的 KV 缓存机制,显著降低推理延迟和成本。
会话后批量存储,减少 API 调用次数: 对话结束后,将整个会话内容(短期记忆)一次性存储到长期记忆系统中,而不是每轮对话都调用存储接口。这样不仅有助于合并记忆片段、提升记忆质量,还能有效控制 API 调用次数,降低费用。
- 性能与成本优化
合理控制上下文长度,避免 token 溢出: 虽然主流大模型支持百万级 token 输入,但实际应用中建议将短期记忆上下文控制在 8000 token 以内,既保证上下文完整性,又不影响推理速度。
减少上下文修改,保持缓存命中率: 大模型推理时,缓存命中(Cached Input)成本远低于普通输入。频繁修改上下文会导致缓存失效,推理成本提升 10 倍以上。因此,除非必要,尽量避免会话中对历史内容进行编辑。
长期记忆采用语义压缩和智能索引: 对长期记忆内容进行归类、摘要和语义压缩,减少冗余数据,提升检索效率。通过语义索引和聚类技术,让 AI 能够快速定位与当前任务最相关的记忆片段。
- 用户体验与安全
系统提示中加载用户档案,提升个性化: 将用户的基础信息(Profile/System Category)直接写入系统提示,让 AI 在每次会话中都能“认识”用户,提供贴心、定制化的服务。
动态记忆与实时场景结合,增强响应能力: 对于用户当前提出的新需求或场景,及时从 Custom/Cluster Category 中检索相关记忆,并附加在用户输入后,确保 AI 响应高度相关和智能。
关注隐私与安全,做好数据保护: 记忆系统涉及大量用户敏感信息,务必采用加密存储、权限管控等措施,确保数据安全和用户隐私。
- 系统扩展与维护
定期清理和归档过期记忆: 随着用户和系统交互的增加,记忆库会不断膨胀。定期清理过期、低价值或重复的记忆内容,保持系统高效运行。
持续优化记忆提取和检索算法: 随着业务需求变化和技术进步,记忆系统的提取、聚类和检索算法也需不断优化,提升智能化和准确性。
多层次记忆结构设计,支持复杂推理: 结合代理式记忆、记忆图连接等先进框架,建立短期记忆、长期记忆、事件记忆等多层次结构,支持跨文件、跨类别的复杂推理,打造真正智能的 AI Agent。
6.3 检索增强生成 RAG :让 AI 查找知识
对话式 AI 要想真正做到“知道更多”,不能仅靠模型的固有知识。
Memory 让模型记住“你是谁、我们聊过什么”,而 RAG 则让模型能够访问“外部世界的知识”。这就像一个有记忆力的朋友,偶尔还会查资料来回答问题。RAG 赋予 对话式 AI 即时检索信息的能力,比如:
客服场景:实时查阅用户订单、工单状态;
金融助理:调取最新汇率、交易记录;
企业助手:检索内部知识库、产品文档;
总而言之,RAG 的核心作用是:通过外挂一个实时、可控的知识库,将 LLM 的强大语言能力与外部知识源的准确性和实时性相结合,从而生成更可靠、更精确、更专业的回答。
6.3.1 什么是 RAG
RAG,全称 Retrieval-Augmented Generation(检索增强生成),是一种让大语言模型在生成回答之前,主动去“查资料”的机制。
可以把它理解为一个“带搜索引擎的大脑”:当用户向模型提问时,RAG 系统不会仅仅依靠模型内部的知识(即训练时学到的内容),而是先到外部数据库、文档、或知识库中检索相关信息,再将这些资料提供给模型参考,从而生成更加准确、最新、具备事实依据的回答。
6.3.2 RAG 的基本架构
RAG 的结构可以分为两部分:
- Retrieval(检索层)
负责在外部知识源(如数据库、向量库、文档库)中检索与用户问题最相关的信息。
常见的检索方式包括基于关键词的搜索(BM25)或基于语义的向量检索(Embedding Search)。
- Generation(生成层)
将检索到的资料作为“上下文提示”传入大语言模型中,让模型在回答时参考这些外部信息。
模型在生成回答时,不再完全依赖自身参数中的知识,而是融合检索结果进行推理与表达。
整个流程如下:
用户提出问题(Query)
检索模块从外部数据中找到相关内容(Documents)
将内容与原始问题拼接,输入给 LLM
模型生成最终回答(Answer)
6.3.3 RAG 和 Memory 区别
很多开发者在实现 对话式 AI 时容易混淆 RAG 与 Memory,因为两者都与“外部知识”有关,但它们在目标和设计上完全不同。
| 项目 | RAG(检索增强生成) | Memory(记忆系统) |
|---|---|---|
| 目标 | 获取最新的事实与知识 | 保留用户的长期历史与个性信息 |
| 数据来源 | 外部知识库、文档、网页 | 内部记忆库(用户交互、上下文) |
| 生命周期 | 每次查询动态检索 | 持续积累并长期保存 |
| 适用场景 | 回答知识性问题(如“今天的汇率”) | 维护连续性与个性化(如“记得我昨天说过…”) |
简单来说:
RAG 是让 AI “会查资料”
Memory 是让 AI “会记事”
而在实际系统中,两者往往是协同工作的。RAG 负责扩展事实边界,Memory 负责延续对话脉络。这让 对话式 AI 既能“了解世界”,又能“了解你”。
6.3.4 对话式 AI + RAG 架构拆解
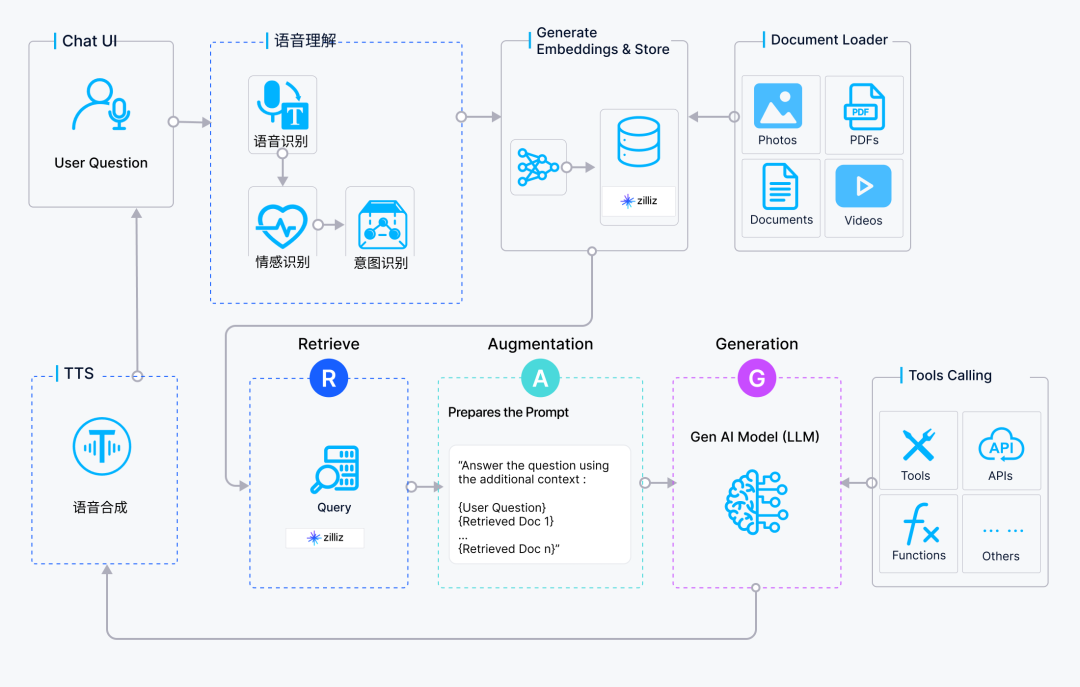
将 RAG 集成到 对话式 AI 中,意味着在系统的决策核心中增加了一个关键的“信息检索”环节。整个系统的架构和工作流程如下:
核心组件
语音输入/输出模块 (ASR & TTS):负责语音与文本之间的相互转换,是用户与系统交互的桥梁。
意图识别与初步处理模块 (NLU & Dialogue Management):快速识别用户意图并决定处理路径。如果是一些简单指令(如“播放音乐”),可以直接执行;如果是一个知识密集型问题(如“介绍一下你们最新的产品特性”),则会触发 RAG 流程。
RAG 核心模块:
信息检索器 (Retriever):这是 RAG 的核心。当收到一个需要外部知识的问题时,检索器会将问题文本(Query)进行向量化(Embedding),然后在向量数据库(Vector Database)中进行高效的相似度搜索。
知识库 (Knowledge Base):这里存储了所有供检索的外部知识。这些知识可以是产品文档、网页、API 数据源等,它们预先被处理、切块(Chunking)并转换成向量形式存储。
向量数据库 (Vector Database):如 Milvus,是专门用于存储和高效查询大规模向量数据的数据库。 当检索器传来查询向量时,Milvus 能够快速返回最相关的文本块(Contexts)。
生成器 (Generator):通常是一个大型语言模型(LLM)。它接收原始的用户问题和从向量数据库中检索到的相关上下文信息,然后生成一个既流畅又精准的回答。
工作流程详解
语音转文本:用户发出语音提问,ASR 系统将其转换为文本。
意图判断:NLU 分析文本,判断这是一个需要 RAG 介入的知识查询任务。
检索 (Retrieve):将用户的问题文本输入信息检索器,检索器在向量数据库中查找最相关的知识片段。
增强 (Augment):将检索到的知识片段与用户的原始问题打包成一个增强的提示(Prompt)。
生成 (Generate):将这个增强的提示发送给 LLM,LLM 基于这些信息生成最终的文本答案。
文本转语音:TTS 模块将生成的文本答案转换成语音,播放给用户。
6.3.5 实践与优化建议
构建一个高性能的 对话式 AI + RAG 系统并非易事,开发者需要关注以下几个关键挑战:
- 延迟问题
语音交互对实时性要求极高。整个“ASR -> NLU -> RAG -> LLM -> TTS”的链条必须在极短的时间内完成,通常要求在半秒以内才能保证对话的流畅性。 RAG 中的检索和 LLM 的生成都是潜在的耗时环节。
最佳实践:优化检索算法、使用高性能的向量数据库(如 Milvus)、选择响应速度更快的 LLM 模型,并采用流式(Streaming)ASR 和 TTS 技术,即边识别/边合成,来缩短用户等待时间。
- 检索质量
RAG 系统的上限取决于检索的质量。如果检索出的内容不相关或质量低下,生成结果也会差。
最佳实践:优化文档的切块策略(Chunking Strategy),改进嵌入模型以更好地理解语义,并采用重排序(Re-ranking)模型来优化检索结果。
- 数据隐私与安全
当知识库包含敏感信息时,如何确保数据在检索和生成过程中不被泄露是一个重要问题。
最佳实践:采用本地化部署方案,对敏感数据进行加密和匿名化处理,并建立严格的访问控制机制。
- 上下文管理
在多轮对话中,如何准确理解用户的指代(如“它怎么样?”),并结合上下文进行有效检索,是一个核心难题。
最佳实践:设计强大的对话管理器来维护和传递对话历史,或者在检索前对用户问题进行改写,融入上下文信息。
通过将 RAG 技术与传统的 对话式 AI 架构相结合,开发者可以构建出远超传统智能音箱能力的、真正“知识渊博”且可靠的语音助手。 它们不仅能处理日常指令,更能成为特定领域的专家,在客户服务、企业知识问答、智能座舱等场景中发挥巨大价值。