2. Conversational AI 的架构与编排
开发者导读:
本章介绍对话式 AI(Conversational AI)系统的核心结构与运行机制。 你将了解一个语音对话式 AI(Conversational AI)是如何从“听懂”到“回应”的,并认识两种主流架构:级联模式(Cascaded) 和 端到端模式(End-to-End)。 我们还将说明为什么仅仅连接 STT、LLM、TTS 并不足以构成一个真正可用的语音代理,以及为什么编排(Orchestration)是让系统“活起来”的关键。
本章目标:
- 理解 对话式 AI 的基本技术结构;
- 区分级联与端到端架构的优缺点;
- 掌握语音编排的核心概念与挑战;
- 理解 TEN 框架在语音系统中的作用。
构建一个能自然对话的对话式 AI,表面上看似只是把语音识别(STT)、语言模型(LLM)和语音合成(TTS)连在一起。但当开发者真正动手实现时,就会发现问题远不止调用几个 API 那么简单。要让系统“像人一样”听、想、说,需要在毫秒级时间内同时完成语音流传输、延迟控制、状态同步和逻辑编排。这一章将介绍对话式 AI 的基础架构,以及为什么“编排(orchestration)”是语音代理中最核心的系统能力。
2.1 Conversational AI 的基本结构
任何一个语音代理的工作流程,都可以抽象成三层:输入 → 理解 → 输出。
在输入层,系统负责采集用户声音、进行回声消除与噪声抑制(AEC、ANS),并通过语音活动检测(VAD)判断语句起止。
在理解层,ASR 将语音转换成文本,LLM 对文本进行语义理解与决策生成,必要时还会触发工具调用(Tool Call)或检索增强(RAG)。
在输出层,TTS 将生成文本实时转换为音频,并通过设备扬声器播放给用户。
这三个层级形成一个完整的语音对话回路,任何环节的延迟或状态错误,都会被用户直接感知。一个真正优秀的 对话式 AI,必须让这些模块以极高的时序精度协同工作。
2.2 两种常见的架构:级联与端到端
当前业界的语音代理实现方式主要分为两类: 级联架构(Cascaded Mode) 和 端到端架构(End-to-End Mode)。
2.2.1 级联架构(Cascaded Mode)
在级联架构中,语音信号按顺序流经多个模块,每个模块负责独立的子任务:
STT(Speech to Text) → LLM(Language Model) → TTS(Text to Speech)
STT 模块将声音转录为文字,LLM 负责生成语义响应,TTS 再将文本转回音频播放。
由于每个部分相互独立,开发者可以针对不同需求替换组件。例如,可以选择擅长识别口音的 STT 引擎,或切换到音色更自然的 TTS 服务。这种模块化设计让系统具有良好的可扩展性和调试性。如果其中一个组件出现问题,只需单独替换,而无需重构整个系统。
缺点也显而易见:多个环节串行传递会增加延迟;各模块需要单独部署与调试;在流式交互场景中,协调与中断逻辑会变得复杂。
尽管如此,在目前的技术阶段,级联仍然是大多数开发者和企业采用的首选方案——稳定、灵活、成本可控。
2.2.2 端到端架构(End-to-End Mode)
端到端架构用单一多模态模型处理整个语音输入到语音输出的过程。
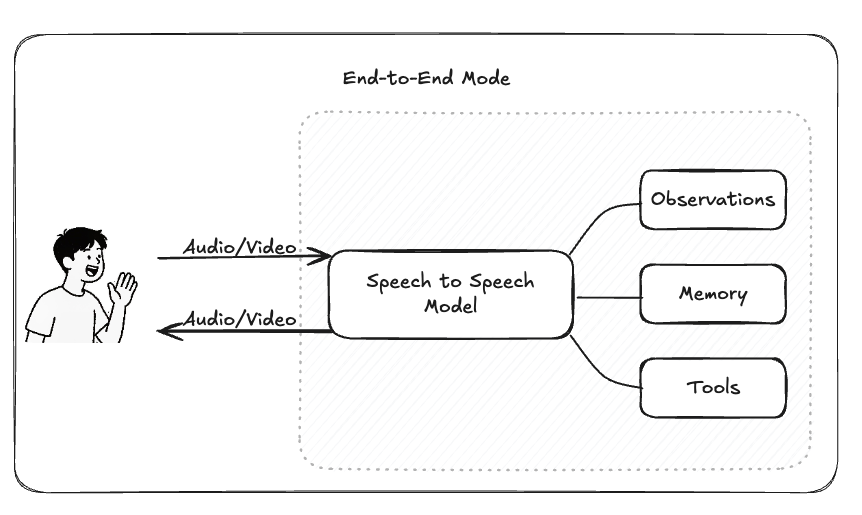
用户说出一句话,系统在内部直接生成语音回应,不再显式分出“识别—生成—合成”的步骤。以 OpenAI 的 Realtime API 为例,它通过一个流式通道,实现“语音进—语音出”的连续对话。这种模式的优势非常突出:延迟极低,响应自然流畅;部署简单,不需要手动维护多个模型。
但与此同时,开发者也失去了控制权。你无法调整识别逻辑、插入工具调用,也无法查看中间文本结果。要适配新的场景,必须重新微调整个模型。此外,端到端模型的输出往往更短、更口语化,缺乏复杂推理链条。
如吴恩达在一次演讲中指出,端到端语音模型仍缺乏文本层面的验证机制,这限制了它在逻辑严谨任务中的表现。
可以说,端到端代表了未来,但级联仍然是现在最现实的选择。 未来几年,我们更可能看到的是二者的混合形式:在关键路径使用级联以保持可控性,辅以端到端模块提升自然度。
2.3 对话式 AI 的编排框架
如果说纯文本的 Agent 像是在与同事邮件往来,那么对话式AI 更像是在主持一档直播电台节目:你得同时兼顾麦克风、节奏、插话以及听众期待。我们所说的 “编排”(orchestration),就是这种在实时性与流畅性之间找到平衡的协调过程——让 STT、LLM、TTS、传输层等模块在多个流(音频流、模型流、控制流、状态流)之间顺畅协作。
几乎每个做对话式 AI 的团队都经历过“手搓期”:先拼一个 STT,再接上 LLM 输出,再调个 TTS 播放——Demo 跑得起来,但当你想加打断、并发、轮次检测或多线程流式处理时,整个系统立刻崩溃。
对话式 AI 从来不是三个 API 的堆叠,而是一个实时分布式系统。
2.3.1 为什么语音编排远比文本复杂
在真正理解“语音编排”是什么之前,先要意识到它为什么比传统文本系统更难。语音对话系统不仅仅处理语义,更要协调时间、流、延迟与中断。
- 延迟极限极低
人类对话中约 200 毫秒 的延迟就会被感知到。电信标准通常认为 150–200 毫秒单向延迟 是自然交流的上限。一个语音智能体必须在总流程(麦克风 → STT → LLM → TTS → 扬声器)内保持远低于一秒的延迟——这还要包括网络抖动与设备限制。
- 全双工轮流发言
与文字聊天不同,一个成熟的语音智能体要能边说边听,并支持打断(barge-in):当用户开始说话时立即中止 TTS。为此需结合VAD(语音活动检测)与语义轮次检测(semantic turn detection)来判断用户是否真的结束或只是停顿,还要跟踪诸如首响应延迟、打断响应性能等指标。
- 全程流式处理
音频是逐帧传入的;STT 必须流式输出中间转录;TTS 也需流式生成音频;传输层(通常为 RTC)必须保持低抖动并进行回声消除。文字智能体可以排队执行任务,而语音智能体必须在实时管线中维持节奏与背压。
- 中断语义
打断并不仅仅是静音。你需要在生成中途取消或引导 LLM、清空 TTS 缓冲、切换状态机——但不能破坏整个会话。(想象成“DJ 按下对讲键”,而不是“拔掉电源”。)
- 动态环境下的质量
麦克风噪声、串音、设备差异都会影响体验。编排需决定哪些步骤在边缘(设备端)处理、哪些在云端处理,以平衡隐私、成本与延迟。
总结而言,传统文本编排关注逻辑与任务,而语音编排关注时间、信号与实时流。它不是“流程引擎”的问题,而是“时序协调”的问题。
那么,这样一个需要协调信号、时间与状态的系统,它的编排究竟是什么样的?
2.3.2 什么是对话式 AI 的编排
对话式 AI 的编排,是让不同模块之间像交响乐一样协同,而不是依次执行脚本。它要回答四个核心问题:
- 谁与谁对话?
在大多数语音智能体框架中,系统会将智能体建模为由节点(extensions、groups)组成的图(graph)。节点之间通过控制流与数据流相连。
图可以是预定义的(随应用启动、可自动加载),也可以是动态生成的(通过命令按需启动)。每个图都描述节点及其连接关系(包括多入/多出模式),并且可以在无需重新编译的情况下进行替换或更新。
- 什么流向哪里?
编排系统通常会区分不同的消息类型,例如 command(带结果)、data、audio_frame、video_frame 等。模块间通过消息名称(类似函数签名)进行绑定,使跨语言组件得以协同,同时保证媒体流在数据平面高效传输。
- 何时何地执行?
编排可以跨线程、跨进程运行,以便提高可用性、支持热更新,并允许灵活配置同步或异步行为。
常见拓扑包括 有向循环图(Directed Cyclic Graph),支持 1→N、N→1、或 N→M 的模式,并能在运行时进行动态调整。
- 如何确保安全与高效?
一个成熟的语音框架会通过消息所有权机制(发送者放弃所有权、借用/归还 API)来保证并发安全,并配合类型系统与模式校验确保模块间数据格式一致。
一些工具(如 check graph)还能帮助开发者在部署前检测图结构是否存在连接错误。
2.4 对话式 AI 框架拆解
在对话式 AI 的实际落地中,通常会有两条路径:企业级方案与开源框架。
前者强调快速接入与稳定性,例如声网推出的对话式 AI 引擎,帮助企业以更高效率将语音智能能力集成到业务系统中。而开源路径则更注重编排灵活性与可扩展性,让开发者能够自由探索不同的系统结构与模型组合。
在这里,我们将以开源生态中的代表 —— TEN Framework 为例,拆解一个真实的对话式 AI 编排框架,看看它如何将抽象的系统理念落地为可运行的架构。
2.4.1 TEN Framework 的编排哲学
- 图是契约
TEN 的 Graph 规范清晰定义节点(extension)与它们的控制/数据/媒体连接。你可以在应用属性中定义预设图(支持 auto_start、singleton),也可以通过发送 start_graph 命令启动动态图。这意味着编排是数据结构,而非硬编码逻辑。
- 控制面与媒体面分离
每个扩展声明自己的 cmd_in/out、data_in/out、audio_frame_in/out、video_frame_in/out。框架通过消息名进行匹配,并自动管理所有权与线程安全。结果是,你无需手写 IPC 逻辑即可实现稳定的全双工音频。
- 跨进程/线程实时可变
TEN 支持跨进程编排与运行时配置。你可以进行 1→N 并行调用、N→1 聚合、或 N→M 链式拓扑——都可在不重新编译的情况下热切换。
- 多语言与多部署形态
扩展可使用 C/C++、Go、Python、JS/TS 等语言实现,可在单进程内并行运行,也可分布在不同机器间(边缘 + 云)。这让低延迟任务(如 VAD、轮次检测)驻留在边缘,而复杂推理留给云端 LLM。
- 实时状态管理
框架强调动态状态,使智能体能在会话中途自适应调整——这对打断处理、轮次切换、语速调节尤为重要。
- 围绕图的一等工具链
TEN 提供图验证工具(tman check graph)与 TMAN Designer 可视化低/无代码编辑器,可加载应用与图、可视化流程与日志——非常适合调试包含 STT→LLM→TTS 等复杂管线。
- 语音原生积木
TEN 内置开源的 TEN VAD(流式、低延迟)与 TEN Turn Detection(语义轮次检测,支持 EN/ZH,“等待/结束/未完成” 状态),显著减少误判与抢话。这些模型可像任意扩展一样直接插入你的图中。
2.4.2 对话式 AI 编排实例
上面讲的是 TEN 在架构层面的设计原则。那这些机制在真实的对话管线中是怎样发挥作用的?下面两个例子可以帮助你更直观地理解语音编排的运行方式。
- 实例一:经典 STT → LLM → TTS(全双工)
最常见的 TEN 管线是全双工的语音对话:
RTC In
→ VAD / Turn Detection
→ STT (流式)
→ LLM (Function Call + RAG)
→ TTS (流式)
→ RTC Out整个过程流式进行。
当用户说话时,VAD 识别语音段并将帧流送入 STT;
STT 输出部分识别结果传给 LLM;
LLM 开始生成 token;
每个 token 实时触发 TTS 生成音频块返回给 RTC。
当用户在系统播放时插话,VAD 会检测到新的音频活动,TEN 会发出控制消息中止当前 TTS,取消 LLM 推理并切回监听状态。
所有这些逻辑都通过图定义完成,无需手写复杂的条件判断。
- 实例二:实时 API 管线(Voice-to-Voice LLM)
另一种架构使用实时多模态 API 替代传统 STT+LLM 组合:
RTC In
→ Realtime API (LLM+ASR)
→ TTS
→ RTC Out在这种模式下,语音识别与语言推理由一个端到端模型完成,TTS 模块只在必要时作为后备或声音克隆组件。即便架构更简单,开发者仍可在 TEN 图中挂载 VAD 和 Turn Detection 模块,以在实时流中实现打断控制和状态管理。
这种混合模式兼顾了端到端的流畅体验与编排系统的可控性。