使用 CRNN、CTC 损失、DeepSpeech Beam Search Decoder 和 KenLM Scorer 进行语音识别

理论
如今,三个最流行的终端到终端的ASR(自动语音识别)模型是 Jasper 、 Wave2Letter + 和 Deep Speech 2 . 。现在它们 可以 作为Nvidia 制作的 OpenSeq2Seq 工具包的一部分使用。所有这些 ASR 系统都基于神经声学模型,它在每个时间步长 t 的所有目标字符 c 上产生概率分布 Pt© ,然后由 CTC 损失 函数评估:
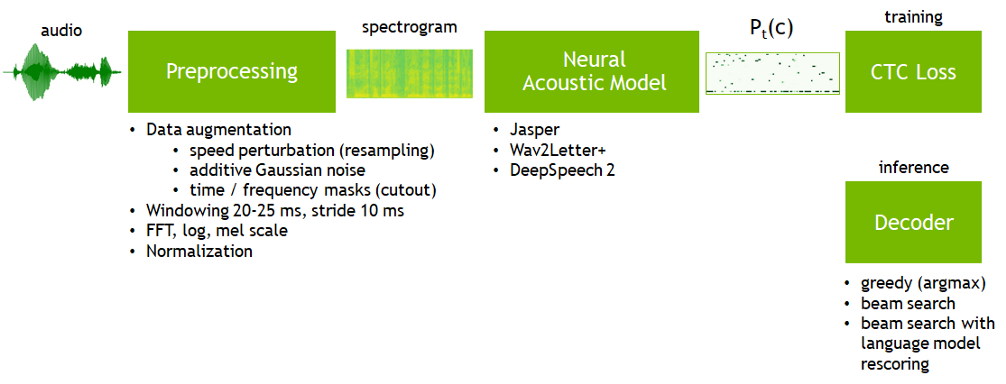
Nvidia对 CTC ASR 管道架构的总结
本质上,本文描述的端到端语音识别系统是由几个简单部分组成的:
- 使用 librosa 或 torchaudio 将原始波形转换为 频谱图 。 本文 提供了对 梅尔频谱图 的直观理解,而 本文 将仔细研究 转换背后 的 数学原理 。
python
import librosa
import librosa.display as display
import torch
import torchaudio
import matplotlib.pyplot as plt
import numpy as np
train_dataset = torchaudio.datasets.LIBRISPEECH("./data", url="train-clean-100", download=True)
waveform, sample_rate, _, _, _, _ = train_dataset[0]
num_channels, num_frames = waveform.shape
audio_transforms = torchaudio.transforms.MelSpectrogram()
spectrograms = audio_transforms(waveform)
img = spectrograms.log2().permute(1, 2, 0)
f, (ax, ax1, ax2) = plt.subplots(3, 1)
f.set_size_inches(15, 8)
ax.title.set_text('Waveform')
ax.grid(True)
ax.plot(torch.arange(0, num_frames) / sample_rate, waveform[0], linewidth=1)
ax1.title.set_text('Mel Spectrogram')
ax1.imshow(img)
spec = np.abs(librosa.stft(waveform.numpy().squeeze(0), hop_length=512))
spec = librosa.amplitude_to_db(spec, ref=np.max)
display.specshow(spec, sr=sample_rate, x_axis='time', y_axis='log')
plt.colorbar(format='%+2.0f dB')
ax2.title.set_text('Spectrogram')
plt.show()
如何使用librosa和torchaudio将波形转换为频谱图
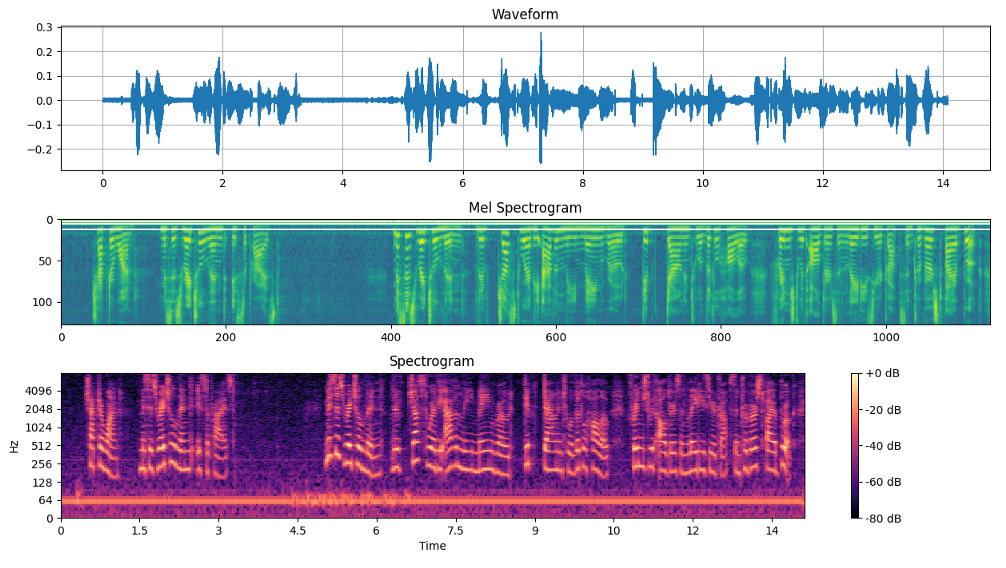
- 频谱图是一幅图像,因此我们可以使用 卷积层 从中提取特征。在这篇文章中,我将使用的当红组合 Conv2d 层和 GELU 激活功能(因为 它 比 RELU 更好)与 dropout 的正规化建设。此外,我认为使用 层归一化 和 跳过连接 以获得更快的收敛和更好的泛化是有益的。因此,神经网络的第一部分将由以下层组成:
# First Conv2d layer</strong>
Conv2d(1, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)) <strong># 7 blocks of these layers
# Skip connection is added to this Conv2d layer</strong>
LayerNorm((64,), eps=1e-05, elementwise_affine=True)
GELU()
Dropout(p=0.2, inplace=False)
Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
**# I will use 5 blocks of these layers**
LayerNorm((512,), eps=1e-05, elementwise_affine=True)
GELU()
GRU(512, 512, batch_first=True, bidirectional=True)
Dropout(p=0.2, inplace=False)
- 实际上,我们需要的是将频谱图图像的每个小的垂直切片映射到某个字符,因此我们的模型将为每个垂直特征向量和每个字符生成概率分布。可以使用 线性 (全连接)层来完成:
<strong># Input for this layer is an output from the last GRU layer
# We need to gradually reduce number of outputs from 1024 to the number of characters used in LibriSpeech dataset - 28 + 'blank'</strong>
Linear(in_features= **1024** , out_features= **512** , bias=True)
GELU()
Dropout(p=0.2, inplace=False)
Linear(in_features= **512** , out_features= **29** , bias=True)
- 然后我们可以使用贪心解码器或波束搜索解码器来生成最终转录。
贪婪解码器取入该模型的输出和每个垂直特征矢量时,它选择具有最高概率的字符。波束搜索译码器稍微复杂。波束搜索基于一种启发式,假设具有高概率的随机变量链具有相当高的概率条件。基本上,它采用p(x1)的k 个最高概率解,然后为每个解采用p(x2|x1)的k 个最高概率解。然后我们需要取 p(x2|x1) * p(x1) 值最高的那些K并重复。
我认为Andrew Ng 的 这个视频 和 这篇文章 是关于这个主题的最直观的指南。
根据谷歌的 这篇 关于 NMT 的 论文 , “……我们发现……调整良好的波束搜索对于获得最先进的结果至关重要。”
- 与 CRNN 模型一样,训练过程中将使用 CTC 损失 。你可以阅读更多关于这方面的损失函数可点击这里、 这里 或 这里 。
- 此外,使用 Levenshtein 距离 和 WER 作为衡量原始话语和生成的转录之间差异的指标非常方便。
生成的模型具有以下架构:
Speech recognition model’s architecture (1,645,181 trainable parameters)
语音识别模型的架构(1,645,181 个可训练参数)


实践
数据集
在本文中,我使用了 LibriSpeech ASR 语料库 ,该 语料库 包含大约 1000 小时 的分段和对齐英语语音,源自阅读有声读物。此数据集中的话语由 28 个 字符(目标类)组成:
```python
target_dir = "./data"
if not os.path.isdir(target_dir):
os.makedirs(target_dir)
train_dataset = torchaudio.datasets.LIBRISPEECH(target_dir, url="train-clean-100", download=True)
test_dataset = torchaudio.datasets.LIBRISPEECH(target_dir, url="test-clean", download=True)
classes = "' abcdefghijklmnopqrstuvwxyz"
然后我们需要使用 MelSpectrogram 将波形转换为频谱图, 并定义函数将文本转换为整数,反之亦然:
audio_transforms = torchaudio.transforms.MelSpectrogram()
num_to_char_map = {c: i for i, c in enumerate(list(classes))}
char_to_num_map = {v: k for k, v in num_to_char_map.items()}
str_to_num = lambda text: [num_to_char_map[c] for c in text]
num_to_str = lambda labels: ''.join([char_to_num_map[i] for i in labels])
这个 collate 函数对于准备我们模型所需的张量是很有必要的—— 谱图和标签以及它们的长度 。这些“长度”张量稍后将被 CTC 损失函数使用:

现在,我们必须初始化 的DataLoader 小号 使用训练和验证数据集和随机种子设置为一个固定值,以获得可重复的结果:

训练
下一步是定义训练和验证循环,选择优化器、超参数和指标来评估训练进度。我决定使用具有 5e-4 的相当低学习率的 AdamW 优化器,将这个模型训练 25 个 时期,并使用 levenshtein 和 jiwer 包来计算质量指标:


训练并验证循环


模型直接遵循上一段描述的架构进行实践
对于推理,我用的 柱搜索解码器 通过 DeepSpeech 。 它允许我们使用基于 KenLM 工具包的 外部语言模型 评分器 。
text_file = open("chars.txt", "w", encoding='utf-8')
text_file.write('\n'.join(list(classes)))
text_file.close()
生成将用于字母表初始化的自定义字母表映射文件

KenLM 模型和外部 .scorer 生成

使用ds-ctcdecoder 的推理过程
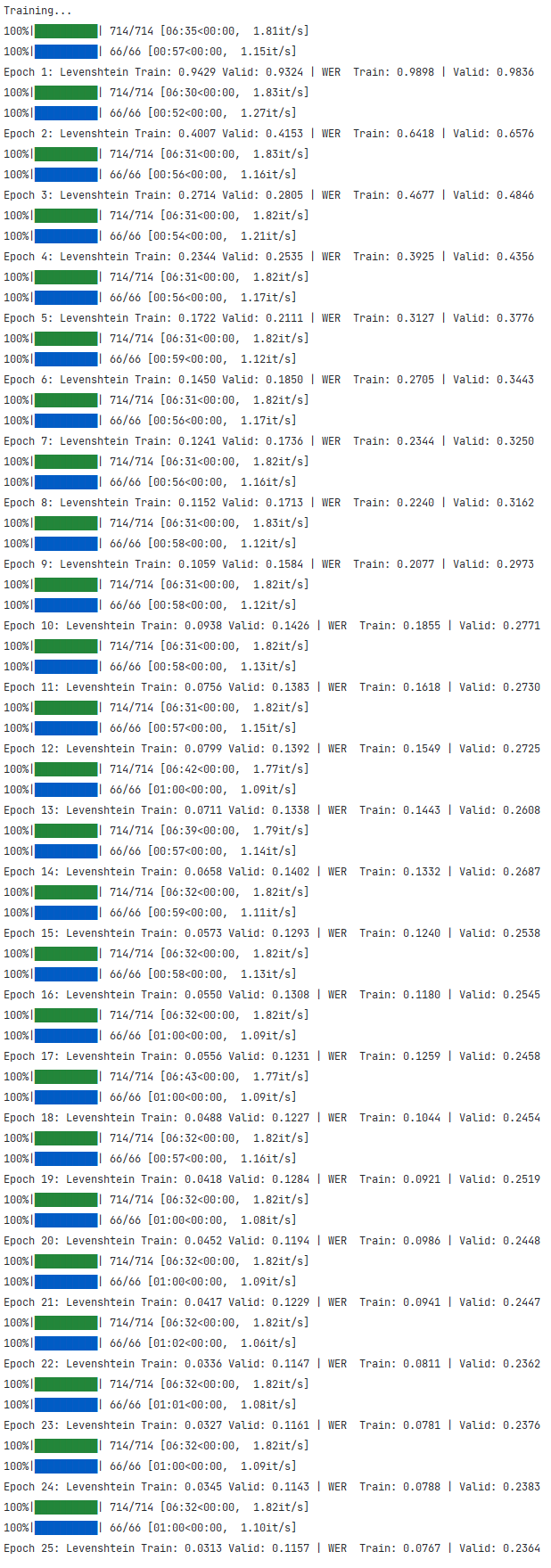
训练和验证结果
预训练中的权重可 在这里 , 和产生的得分手,请 点击这里 。另请注意,批量大小是根据可用 GPU 内存量选择的,并且该模型在训练期间消耗了大约 22 GB的 VRAM :

用于此项目的 CUDA 设备
测试
出于测试目的,我从测试集中抽取了 20 个随机频谱图:
模型推断和显示频谱图
测试集中几个随机样本的结果
如你所见,这个相对较小的模型绝对能够识别人类语音,并在 LibriSpeech 数据集上表现出良好的性能。
这个项目也可以 在我的 GitHub 上找到 。
原文作者 Nikita Schneider
原文链接 https://medium.com/geekculture/audio-recognition-using-crnn-ctc-loss-beam-search-decoder-and-kenlm-scorer-24472e43fb2f